Revolution oder Evolution? Wie Big Data die IT verändert
Herkömmliche Daten-Tools scheitern an Big Data. Mit den zunehmenden Informationsmassen deutet sich deshalb auch ein technologischer Umbruch an. Die jahrzehntelang praktizierte serielle Datenverarbeitung wird zusehends abgelöst von verteiltem Rechnen, relationale Datenbank-Systeme mit ihrer starren Tabellenstruktur werden häufig ergänzt um flexiblere Ansätze. Ist das der Tod der klassischen IT?

„Datenbank“ (Fotolia).
Big Data hin oder her: Daten in jeglicher Form und Größe haben Unternehmen schon immer interessiert. Schließlich lassen sich sich profitbringend einsetzen und bei wichtigen Entscheidungen ist es besser, sich auf Fakten statt auf die Intuition zu verlassen. Reine Rohdaten, wie sie etwa von Kunden kommen, sind allerdings nur von geringem Wert. Um die Rohdaten in Informationen zu transformieren, müssen sie bereinigt, aufbereitet und analysiert werden.
Aus diesem Grund werden Daten in Datenbanken erfasst, konsolidiert und in eine Form gebracht, die sie für Analyseinstrumente zugänglich macht. Business Intelligence (BI) nennt sich die Kunst, sie in wertvolle Informationen zu verwandeln. Die traditionelle BI nutzt als Datenquelle nicht einen chaotischen Datenhaufen, sondern wohlstrukturierte, relationale Datenbanken. Sie bilden oft die Basis für Data Warehouses, also die optimierte Datensammlung eines Unternehmens.
Relationale Datenbanken verlangen Datenstrukturen in Form von Tabellen, also Zeilen und Spalten. Diese Tabellenstruktur dominierte die Datenspeicherung und -analyse seit Jahrzehnten und setzt voraus, Daten im Vorfeld so aufzubereiten, dass sie in das Tabellen-Korsett passen. Mit Big Data wird nun alles anders – oder zumindest schwieriger.
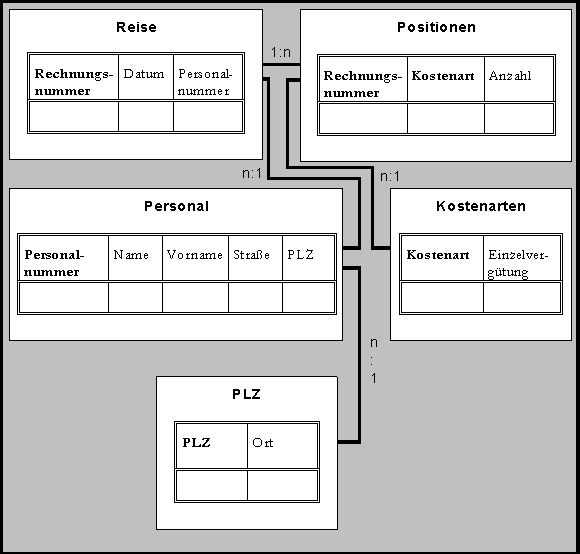
Tabellenstruktur: Die üblichen relationalen Datenbanken speichern Daten als miteinander verbundene Tabellen – große unstrukturierte Datenmengen sprengen dieses Konzept. Quelle: Tecchannel/HDM Stuttgart.
Das Scheitern klassischer Systeme
Worum es bei Big Data geht, ist krass ausgedrückt und auf einen Nenner gebracht: Strukturierte und unstrukturierte Daten im Umfang mehrerer Terabyte und Petabyte müssen mit hoher Geschwindigkeit gespeichert und sehr schnell oder gar in Echtzeit verarbeitet und analysiert werden. Das ist der Extremfall, aber was bedeutet das im Einzelnen für Datenbanken und IT-Systeme?
Da wäre erstens die Größe. Die – vor allem im Kontext von Social Media – zunehmenden Datenquellen und -mengen überfordern herkömmliche Datenbanken. Keine relationale Datenbank kann unlimitiert Informationen aufnehmen. Eine übliche Datenbank wird umso langsamer, je mehr Daten zu verwalten sind und je mehr Relationen für eine Abfrage herangezogen werden. Die Performance, die für Abfragen mit akzeptablen Zugriffszeiten erforderlich ist, wird nicht erreicht. Zwar gibt es inzwischen Optimierungen für große Datenbanken, aber ab einer bestimmten Tiefe und Komplexität kann die beste Optimierung nicht mehr helfen. Eine lokale Datenhaltung stößt an technische Grenzen.
Neben der schieren Masse gibt es zweitens das Problem der unstrukturierten Daten, im Social-Media-Umfeld sind das vor allem Videos und Texte. Sie sind ein Riesenproblem, denn Daten ohne Struktur „sprengen“ das Relationenmodell förmlich: Weil unstrukturiert, lassen sie sich schwerlich ins Tabellenschema pressen. Tabellenorientierte Datenmodelle sind nicht darauf ausgerichtet, mit Unmengen an chaotischen Daten zu arbeiten. Und Social Media wie Facebook und Twitter eine relationale Struktur aufzuzwängen, ist kaum machbar.
Ein weiteres, drittes Problem: Im Gegensatz zur klassischen BI, als es noch Stunden dauerte, um Berichte im Batchverfahren zu generieren, werden heutzutage Ad-hoc-Abfragen mit Analyseergebnissen möglichst in Echtzeit erwartet, die die Grundlage für umgehende, proaktive Entscheidungen bilden oder sogar ein automatisiertes Eingreifen ermöglichen. Und die Ergebnisse solcher Analysen möchten heute nicht nur der Unternehmens-Chef oder CIO, sondern auch Abteilungsleiter und andere Entscheidungsträger bis hin zum Sachbearbeiter.
Tabellenorientierte Datenmodelle sind nicht darauf ausgerichtet, die Unmengen an chaotischen Daten wie Twitter-Tweets zu verarbeiten. Abbildung: Twitter-Kanal der QSC-Pressestelle. Direkt dorthin kommen Sie per Klick auf das Bild.
Alt, aber effektiv: Teile und herrsche
Wie speichert und verarbeitet man dann Big Data effizient? Das Grundprinzip ist uralt und lautet: „Teile und herrsche.“ Statt die Daten an einem zentralen Ort zu speichern und zu verarbeiten, werden sie verteilt und parallel bearbeitet.
Große Daten speichert man am besten im Rahmen einer so genannten „Shared-Nothing-Architektur“ auf verschiedenen Rechnern. Mehr Speicherplatz kann ganz einfach dadurch geschaffen werden, weitere Server neben die bereits bestehenden zu stellen. Jede einzelne Maschine, die so Daten speichern kann, betreibt einen Datenknoten als Dienst, der den Zugriff auf die Daten verwaltet.
Ähnlich wird die Verarbeitung der Daten verteilt, indem die Rechenprozesse auf die Server verlagert werden, auf denen die dafür nötigen Daten liegen. Die Gesamtaufgabe wird also in einzelne Teilaufgaben aufgespalten, die parallel laufen und auf mehreren Rechnern abgearbeitet werden. Sind die Teilaufgaben gelöst, werden die Ergebnisse eingesammelt und zusammengefügt.
Diese Parallelisierung schlägt gleich mehrere Fliegen mit einer Klappe: Da die selben Rechner zum Speichern normalerweise auch für Berechnungen genutzt werden, kann man die Zugriffe optimieren. Statt dass die Daten aufwändig über das Netzwerk zum Rechner geschoben werden müssen, „kommt die Berechnung zu den Daten“. Das erhöht die Leistung und steigert die Geschwindigkeit. Damit löst sich auch das oben erwähnte Problem Nummer 3, dass heutzutage Ad-hoc-Abfragen mit möglichst schnellen Analyseergebnissen – oft in Echtzeit – erwartet werden.
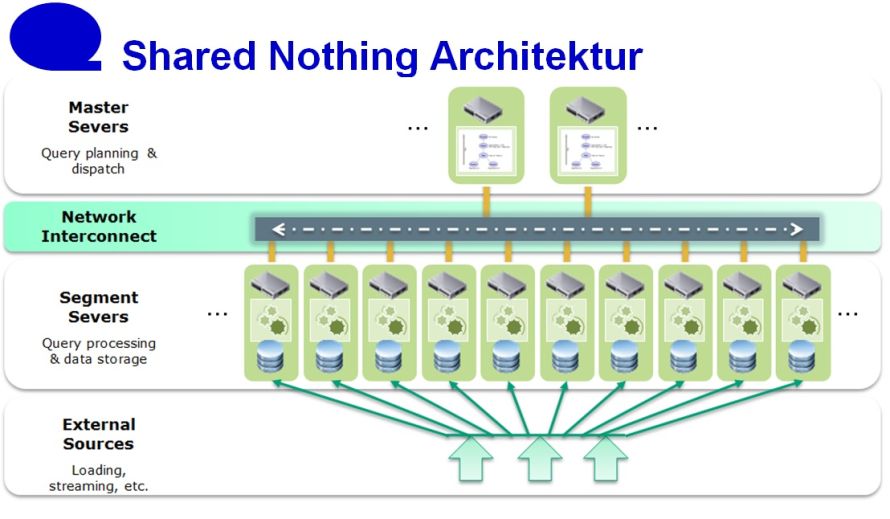
In einer Shared-Nothing-Architektur erhält jeder Knoten einen Teil der Gesamtdaten, die er mit seinen eigenen Ressourcen bearbeitet. Quelle: Data Mart / Computerwoche. Zum Vergrößern der Abbildung bitte Grafik anklicken.
Chaos im Griff
Und noch ein paar Pluspunkte hat die Parallelisierung, nämlich Skalierbarkeit, Ausfallsicherheit und Kosten. Man kann mit nur wenigen Servern klein anfangen und bei Bedarf weitere hinzufügen. Im Grunde lässt sich die Infrastruktur linear und ohne Obergrenze beliebig skalieren. Die Daten können automatisch auf mehrere Knoten repliziert werden, um die Konfiguration fehlertolerant zu machen. Fällt ein Server aus, kann die entsprechende Aufgabe auf dem Ersatzserver mit dem Datenduplikat fortgeführt werden.
Spezielle, teure Server sind dafür nicht notwendig. Cluster aus gängigen und preiswerten Servern mit einem oder zwei CPUs und ein bis zwei Terabyte Flash-Storage reichen aus, um die Rechenleistung und Geschwindigkeit zu liefern, die für die parallele Verarbeitung in einem verteilten Netz nötig sind. Flash-Storage, also SSDs, sind besser geeeignet als herkömmliche Festplatten, weil sie deutlich schneller sind.
Damit verbleibt noch die typische Unstrukturiertheit von Big Data als Problem. Auch hier findet gerade ein Wandel statt. Die relationalen Datenbanken werden zunehmend ergänzt um nicht-relationale Konzepte wie „NoSQL-Systeme“. Solche NoSQL-Datenbanken benötigen keine festgelegten Tabellenschemata und setzten sich im Big-Data-Umfeld immer mehr durch.
Aufgrund ihres einfachen Aufbaus können sie als schneller Datenspeicher mit extrem hohen Durchsatzraten genutzt werden. NoSQL-Datenbanken lassen sich außerdem auf die Serverknoten in einem Cluster verteilen und ermöglichen deshalb eine fast lineare Skalierbarkeit und hohe Fehlertoleranz. Die Abfragen selbst ähneln den Abfragen in relationalen Datenbanksystemen. Mehr dazu in den nächsten Beiträgen.
Revolution oder Evolution?
Was bedeutet das alles für unsere gewohnte IT? Müssen wir sie bald zum Alteisen geben und die jahrzehntelang bewährten Konzepte, Algorithmen und IT-Systeme wie Datenbanken über Bord werfen? Einer der bekanntesten Vertreter diese These ist Oliver Bussmann, neuerdings CIO der Schweizer Bank UBS, der zuvor CIO von SAP war. „Relationale Datenbanken spielen in zehn Jahren im Enterprise-Umfeld keine große Rolle mehr“, hatte Bussmann im CIO-Jahrbuch 2012 gewettet. Er beruft sich in seiner Argumentation auf technische Entwicklungen, „die relationale Datenbanken überflüssig machen werden“.
Beispielsweise verfallen die Preise für Arbeitsspeicher (RAM) immer mehr, sagt Bussmann, dadurch werde es immer billiger, Daten im schnellen Hauptspeicher vorzuhalten anstatt in trägen Massenspeichern. Zudem könnten hochgradig parallel arbeitende Prozessorkerne eine Arbeitsgeschwindigkeit ermöglichen, „die vor kurzer Zeit noch unmöglich erschien“.
Hat Bussmann mit der These vom Tod der relationalen Datenbank Recht? „Da würde ich mich schon wundern“, erwidert Andreas Bitterer, Research Vice President und Datenbankexperte bei Gartner. Die Ankündigung eines Paradigmenwechsels streife regelmäßig durch die Branche, argumentiert der Analyst in einem CIO-Beitrag – „erst wurde angeblich alles in Objekten gespeichert, dann in XML-Dokumenten“.
Relationale Datenbanken seien aber trotz der neuen Entwicklungen nicht verschwunden, im Gegenteil: „Sie haben die neuen technischen Möglichkeiten einfach aufgesogen, wurden funktional erweitert und sind dadurch immer noch modern.“ Das wird auch mit der Technik wie Massive Parallel Processing passieren, über die heute gesprochen wird.
Ob relationale Datenbanken in zehn Jahren immer noch aussehen wie heute, sei eine andere Frage, sagt Bitterer. Fest steht für den Analysten hingegen, dass Unternehmen auch in zehn Jahren noch relationale Datenbanken benötigen: „Es wird sie natürlich weiter geben, schließlich sind sie allgegenwärtig.“ Also fällt die Big-Data-Revolution wohl aus, aber es wird starke evolutionäre Veränderungen geben.
Unsere Big-Data-Serie im Überblick:
- Big Data: Was dahinter steckt
- Was kann Big Data?
- Revolution oder Evolution: Wie Big Data die IT verändert
- Big Data: Teile und herrsche mit Hadoop
Lesen Sie auch die Artikelserien von Klaus Manhart auf dem QSC-Blog zu…
Kommentare