Big Data: Teile und herrsche mit Hadoop
Der Königsweg, die Datenmassen in den Griff zu bekommen, ist das uralte Prinzip „Teile und herrsche“. Praktisch realisiert wird das meist mit Hilfe der Analyseplattform Hadoop. Mit der Aufteilung der Daten in kleinere Portionen und deren paralleler Bearbeitung auf billigen Standardrechnern hat sich Hadoop als aktueller Branchenstandard für Big-Data-Umgebungen durchgesetzt. Wer das Framework optimal nutzen will, sollte an ein paar Stellschrauben drehen.
Kleiner Elefant für große Daten – Hadoop. Bild: Apache.org.
Wie in meinem vorigen Beitrag auf dem QSC-Blog „Wie Big Data die IT verändert“ angedeutet, ist Verteilung und Parallelisierung der Königsweg, um die Big-Data-Problematik in den Griff zu bekommen.
Viele Vorteile durch Verteilung
Die Grundidee: Rechenprozeduren werden in viele kleine Teilaufgaben zerlegt und auf mehrere Server verteilt. Verwendet werden in der Regel preiswerte Standardserver.
Das Verlagern der Daten auf eine Vielzahl von Knoten und deren Verarbeitung an ihrem Ablageort hat viele Vorteile: So erhöht sich die Leistung dramatisch und beschleunigt die Auswertung der Daten. Die Parallelisierung ist zudem hochflexibel: Man kann mit wenigen Servern klein anfangen. Reichen diese nicht aus, lassen sich weitere hinzufügen. Das kann im Prinzip endlos fortgesetzt werden. Selbst wenn Tausende von Servern eingesetzt werden, lässt sich das Cluster immer noch um weitere Rechner aufstocken.
Die Parallelisierung mit handelsüblichen Servern ist zudem recht kostengünstig – eine wichtige Voraussetzung für eine breitere Akzeptanz dieses Ansatzes. Außerdem lässt sich mit diesem Server-Cluster leicht eine fehlertolerante Konfiguration umsetzen. Fällt ein Server aus, kann die entsprechende Aufgabe auf einem Rechner mit einem Datenduplikat fortgeführt werden.
Der Map-Reduce-Algorithmus
Als De-facto-Standard beim verteilten Rechnen hat sich der von Google entwickelte Map-Reduce-Algorithmus durchgesetzt, der in der Hadoop-Plattform Anwendung findet. Die beiden wichtigsten Bausteine dieses Ansatzes sind erstens ein distributives Dateisystem, das Daten über den lokalen Speicher eines Clusters verteilt und zweitens eine Instanz, die ein Problem in Teilaufgaben aufgliedern und die Ergebnisse wieder zusammenfügen kann.
Der Google-Algorithmus verwendet dazu einen „Koordinator“, der die Datenmassen aufsplittet und sie anhand von vordefinierten Regeln auf die einzelnen Server verteilt. Jeder dieser Server speichert und bearbeitet nur den ihm zugewiesenen, winzigen Ausschnitt der Daten. Bei einer Berechnungsanfrage verteilt der Koordinator die Aufgaben auf in der Nähe befindliche Server. Da die Tasks den einzelnen Serverknoten zugeordnet werden (= Mapping), werden sie als „Map-Tasks“ bezeichnet.
Die Map-Tasks berechnen zunächst Zwischenergebnisse, die der Koordinator bei Bedarf sortiert und in einem temporären Speicher ablegt. Sind alle Zwischenergebnisse kalkuliert, ist die Map-Phase beendet. Das Endergebnis wird dann durch Aggregation, das heißt durch Kombinieren, Zusammenführen und Konsolidieren der Zwischenergebnisse in einem so genannten Reduce-Vorgang berechnet. Daher werden diese Tasks als „Reduce-Tasks“ bezeichnet.
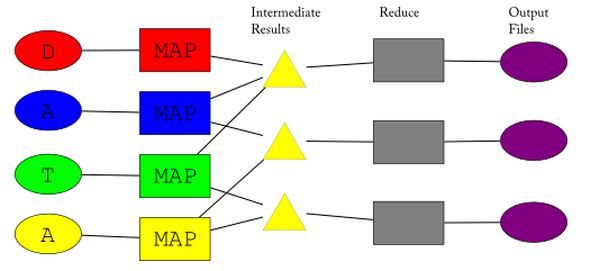
Das Bild illustriert den Datenfluss bei der Map-Reduce-Berechnung. Quelle: Wikipedia / Ville Tuulos.
{kind=link}
Der Datenfluss beim Map-Reduce-Algorithmus:
- Die Eingabedaten („D, A, T, A“) werden auf eine Reihe von Map-Prozessen verteilt (bunte Rechtecke), welche jeweils die vom Nutzer bereitgestellte Map-Funktion berechnen.
- Die Map-Prozesse werden idealerweise parallel ausgeführt.
- Jede dieser Map-Instanzen legt Zwischenergebnisse ab (dargestellt durch die gelben Dreiecke).
- Von jeder Map-Instanz fließen Daten in eventuell verschiedene Zwischenergebnisspeicher.
- Sind alle Zwischenergebnisse berechnet, ist diese sogenannte Map-Phase beendet und die Reduce-Phase beginnt.
- Für jeden Satz an Zwischenergebnissen berechnet jeweils genau ein Reduce-Prozess (graue Rechtecke) die vom Nutzer bereitgestellte Reduce-Funktion und damit die Ausgabedaten (violette Ovale).
- Die Reduce-Prozesse werden idealerweise auch parallel ausgeführt.
Big-Data-Standard Apache Hadoop
Eine konkrete Implementierung des Map-Reduce-Algorithmus ist Apache Hadoop. Die verteilt arbeitende Software realisiert die eben beschriebenen Parellel-Computing-Prinzipien und besteht aus den beiden zentralen Bestandteilen:
- Dem Hadoop Distributed File System (HDFS): Es erreicht hohe Fehlertoleranz und hohe Performance durch das Aufteilen und Verbreiten von Daten über eine große Zahl von Arbeitsknoten.
- Der Hadoop MapReduce Enginee: Sie nimmt Aufträge von Anwendungen an und unterteilt diese Aufträge in kleinere Aufgaben, die es verschiedenen Arbeitsknoten zuordnet.
Vor fünf Jahren hat die Apache Software Foundation die Hadoop-Plattform als Open Source freigegeben. Das in Java geschriebene Framework lässt sich auf mehrere tausend Server skalieren, arbeitet fehlertolerant und gilt als Branchenstandard für Big-Data-Umgebungen.
Inzwischen ist um Hadoop ein regelrechter Hype entstanden. Doch der dürfte Hand und Fuß haben. Die Analysten von IDC glauben, dass der Markt für Hadoop von 77 Millionen Dollar im Jahr 2011 auf 812,8 Millionen Dollar bis 2016 ansteigen wird. Das entspricht einer durchschnittlichen Steigerung von 60,2 Prozent pro Jahr.
Schnellere Datenanalysen
Für den praktischen Betrieb von Hadoop genügen Mainstream-Ressourcen, wie sie im Handel erhältlich sind: Prozessoren, Storage- und Netzwerkkomponenten. Doch um das Beste aus Hadoop herauszuholen, sollten die Hardware-Komponenten jüngeren Datums und aufeinander abgestimmt sein, so dass ein Gleichgewicht geschaffen zwischen CPU, Storage und Netzwerken wird.
Der Hardware-Hersteller Intel hat mit einer Reihe von Benchmarks überpüft, welche Auswirkungen die einzelnen Komponenten auf die Hadoop-Performance haben. Eines dieser Performance-Elemente ist die Geschwindigkeit der CPU. Beim Hardware-Test mit Prozessoren zeigte sich, dass ein Upgrade von einem Intel Xeon Prozessor X5690 auf einen neueren Intel Xeon E5-2690 die benötigte Zeit, um 1 TB Daten in einem Hadoop-Cluster mit 10 Knoten zu sortieren, etwa um die Hälfte reduzierte: Brauchte der X5690 noch 250 Minuten, reichten beim E5-2690 125 Minuten.
Schlüsselfaktor beim Arbeiten mit großen Datenmengen ist der schnelle Zugriff auf nicht-sequentielle Daten. Ein nächster Test untersuchte deshalb, wie sich SSDs im Vergleich zu konventionellen HDD-Festplatten auswirken. Schließlich haben SSDs dramatisch höhere Random-Read-Zeiten. Das Ergebnis: Aufbauend auf der Performance-Verbesserung vom Prozessortest reduzierte der Austausch einer HDD durch eine Intel SSD 520 die Zeit für den kompletten Sortier-Workload um weitere 80 Prozent: Von etwa 125 Minuten auf 23 Minuten.
Aufgrund der verteilten Natur der Hadoop-Workloads hat aber auch das Netzwerk massive Auswirkungen auf die Performance von Hadoop. Aufbauend auf den Verbesserungen durch den Prozessor-Upgrade und den SSD-Einsatz reduzierte ein Upgrade der Cluster-Hardware von 1 Gigabit Ethernet (1GbE) auf 10 Gigabit Ethernet (10 GbE) die Verarbeitungszeit weiter um zusätzliche 50 Prozent: Von etwa 23 Minuten bis auf etwa 12 Minuten. Insgesamt hat sich mit der Optimierung der Komponenten eine Performanceverbesserung von 250 auf beeindruckende 12 Minuten ergeben.
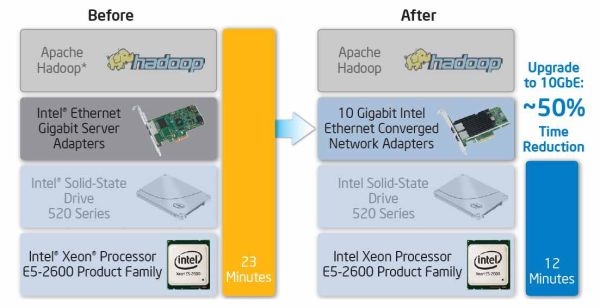
Tests von Intel beweisen: Mit schnelleren Prozessoren, SSDs und neuerer Netzwerktechnologie lässt sich die Hadoop-Performance deutlich steigern. Quelle: Intel.
Explodierende Hadoop-Ökosysteme
Solche Performancetests hat Intel zum Anlass genommen, eine eigene, hardware-optimierte Hadoop-Distribution auf den Markt zu bringen. Sie ist speziell auf die neuen Funktionen in Intels Prozessoren zugeschnitten und für SSDs und 10 GbE angepasst.
Doch optimierte Hadoop-Distributionen gibt es inzwischen von vielen Anbietern. Rund um Hadoop entwickelt sich gerade ein regelrechtes Ökosystem von Herstellern, darunter etliche bekannte Software- und Datenbankanbieter, die leicht handhabbare Hadoop-Werkzeuge oder Zusatzlösungen anbieten. Dass sich die marktbeherrschenden IT-Konzerne hinter Hadoop stellen, ist ebenfalls ein Zeichen dafür, dass das Framework tatsächlich auf dem Weg zum Mainstream ist.
So haben, wie Intel, auch IBM und Oracle eigene Distributionen gebaut und Hadoop um zusätzliche Tools ergänzt. IBM beispielsweise hat die eigene Software „InfoSphere BigInsights“, die in erster Linie für die Analyse unstrukturierter Daten ausgelegt ist, um Hadoop-Technik erweitert. Die neue IBM-Appliance PureData System for Hadoop vereint Hardware und Software und soll die schnelle und einfache Umsetzung von Hadoop-Szenarien ermöglichen.

Puredata for Hadoop integriert das Hadoop-Framework in IBM-Hardware. Quelle: IBM.
Neben den großen Anbietern existiert eine Reihe kleinerer Firmen, die sich auf Produkte und Services rund um Hadoop spezialisiert haben. Cloudera beispielsweise entwickelt neben einer eigenen Hadoop-Distribution Zusatzprodukte wie einen Desktop als Graphical User Interface (GUI), das die Administration von Hadoop-Clustern einfacher und komfortabler machen soll.
Wer keine eigene Hadoop-Lösung aufbauen will, findet auch Cloud-Lösungen. Savanna, ein Gemeinschaftsprojekt mehrere Software-Anbieter wie Red Hat und und Mirantis, erleichtert Anwendern die Installation eines Hadoop-Clusters auf einer Cloud-Infrastruktur.
Amazon.com bietet schon seit längerem in seiner Elastic Compute Cloud (EC2) mit Elastic MapReduce einen Hadoop-Cluster aus der Cloud zur Miete an.
Und Microsoft hat mit HDInsight einen Service für seine Azure-Plattform im Portfolio, der Anwendern das Einrichten und Verwalten von Hadoop-Clustern in der Cloud erleichtern soll.
Unsere Big-Data-Serie im Überblick:
- Big Data: Was dahinter steckt
- Was kann Big Data?
- Revolution oder Evolution: Wie Big Data die IT verändert
- Big Data: Teile und herrsche mit Hadoop
Kommentare
Sollte man besser die Hadoop Basisversion von Apache verwenden oder ein Hadoop-Paket irgendwelcher Distributoren? Was wird hier empfohlen?
http://ibmexperts.computerwoche.de/forum/analytics-big-data/welche-hadoop-distribution