NoSQL und In Memory – die neuen Datenbanken für Big Data

QSC-Bild-Collage: Unstrukturierte Daten wie etwa Fotos können nicht oder nur mit hohem Aufwand in tabellenorientierten Datenbanken gespeichert werden. Neue Datenbankvarianten sorgen für Abhilfe.
Beim Handling von Bildern, Videos und Audiofiles oder Milliarden von Facebook- und Twitter-Einträgen stoßen herkömmliche, tabellenorientierte Datenbanken an ihre Grenzen. Die relationale Datenbanksysteme müssen deshalb um neue Ansätze ergänzt werden. Dazu gehören NoSQL- oder In-Memory-Datenbanken. Doch werden diese in der Praxis auch angenommen?
Daten werden in Datenbanken gespeichert, so weit so gut. Doch was, wenn die Daten riesig groß werden. Und sich nicht in die Tabellenschemata pressen lassen, die die Datenbanktheorie und –praxis dominieren? Deren Software-Realisierungen – DB2, Oracle, Microsoft SQL Server und wie sie alle heißen – haben in den vergangenen Jahrzehnten den Datenbankmarkt bestimmt. Mit Big Data stoßen sie nun ernsthaft an ihre Grenzen.
Das Dilemma: Relationale-Datenbank-Systeme können schlecht mit großen und unstrukturierten Daten umgehen. Unstrukturierte Daten sind Daten, wie sie heute vor allem bei den neuen Medien auftreten. Dazu zählen Texte, Bilder, Audiofiles oder Videodateien – also der Löwenanteil an Datentypen im Social-Media-Umfeld. Diese Daten können nicht oder nur mit hohem Aufwand in Tabellen gespeichert werden – wie in einem der letzten Blogs demonstriert. Vor allem reichen die Verarbeitungsgeschwindigkeiten der herkömmlichen Datenbanken nicht dafür aus.
Man könnte diese Daten als ein wenig wichtiges Randphänomen abtun. Doch das stimmt nicht. Unstrukturierte Daten gewinnen immer mehr Praxisrelevanz. So will sich die Mehrheit der Führungskräfte (58 Prozent) laut einer Capgemini-Studie bei der Datenauswertung auf solch nicht strukturierte Daten wie Texte, Sprachnachrichten, Bilder und Videos stützen. Sie müssen künftig in Entscheidungsprozesse mit einbezogen werden.
Nicht nur SQL: NoSQL-Datenbanken
Datenbank-Systeme sollten deshalb heute die Möglichkeit bieten, nicht-relationale Konstrukte abzubilden. Für diesen Datentypus bieten sich NoSQL-Datenbanken an. Sie sind der Name einer Bewegung weg von den relationalen Datenbanken hin zu neuen beziehungsweise vergessenen Datenbankmodellen. Der Begriff „NoSQL“ steht dabei nicht für „kein SQL“, sondern für „nicht nur SQL“ (= not only SQL).
NoSQL soll bestehende Datenbanktechnologien also nicht ersetzen, sondern ergänzen und zusätzlich zu den klassischen Datenbanken eingesetzt werden. Sie können dann wieder in strukturierte Datensysteme überführt und als Kennzahlen beispielsweise in ein Datawarehouse eingespeichert werden. Der Unterschied zu SQL-Datenbanken ist nicht so groß, wie man meinen möchte, zumal die Abfragen dieser Nicht-SQL-Datenbanken jenen in SQL ähneln.
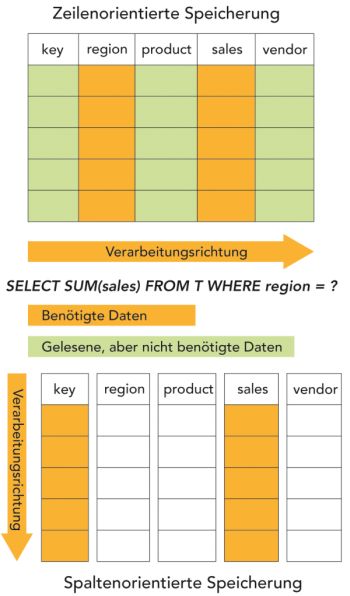
Spaltenorientierte Datenbanken lesen nur die wirklich benötigten Daten ein. Quelle: Computerwoche. Zum gesamten Computerwoche-Artikel klicke auf das Bild.
Bei NoSQL-Datenbanken gibt es mehrere Varianten, die auf jeweils spezifische Probleme zugeschnitten sind. Am verbreitetsten ist die spaltenorientierte „Wide Column Datenbank“. Sie verarbeitet am besten strukturierte umfangreiche Daten, die sich in relationalen Datenbanksystemen nicht gut abbilden lassen. Diese Art von Datenbanken macht sich die Tatsache zu nutze, dass die Anzahl der Zeilen zwar riesig, die Zahl der Spalten jedoch vergleichsweise gering ist. Zudem beziehen sich Abfragen oft nur auf eine Teilmenge der Spalten.
In den üblichen zeilenorientierten Datenbanken müssen für jede Abfrage alle Spalten gelesen werden. Das ist bei großen Daten, also vielen Zeilen, ineffizient. Bei spaltenorientierten Datenbanken wird der Zugriff hingegen lediglich auf die Spalten beschränkt, die für die Abfrage relevant sind. Da es nur wenige Spalten pro Datensatz gibt, kann die ganze Spalte in einem Schritt gelesen werden. Die zu lesende Datenmenge lässt sich so erheblich reduzieren.
Navigieren im Netz: Graphen-Datenbanken
Um die parallele Verarbeitung zu vereinfachen und Analysen zu beschleunigen können Spalten in mehrere Bereiche unterteilt werden. Da die Spaltendaten zudem einen einheitlichen Datentyp haben und es oft nur wenige unterschiedliche Werte je Spalte gibt, können diese Werte extern zusammen mit verweisenden Zeigern gespeichert werden. Damit lässt sich die Datenbank stark komprimieren und Speicherkapazität und –kosten reduzieren.
Eine andere Variante von NoSQL-Datenbanken sind Graphen-Datenbanken. Bei diesen Datenbanken werden unstrukturierte Daten in Diagrammen durch Knoten und Kanten zusammen mit ihren Eigenschaften gespeichert. Das dabei oft genutzte Datenbankformat RDF „Resource Description Framework“ stellt ein Format ohne fixes Schema bereit, das die Informationen innerhalb der Graphen speichert. Eine typische Anwendung dafür ist die Darstellung von Nutzerbeziehungen innerhalb von sozialen Netzwerken.
Der Vorteil liegt vor allem in einem simplen und effizienten Durchlauf (Traversierung) durch ein solches Netz, was sich mit relationalen Datenbanken nur mühselig abbilden lässt. Traversierung eines Graphen bedeutet, dass der Graph beginnend von einem Startknoten durchlaufen wird. Dies stellt eine der wichtigsten Operationen in diesem Modell dar. So können aufwendige Datenbankabfragen wie mehrere rekursiv verschachtelte „Joins“ – Verknüpfugen zwischen Tabellen – vermieden werden.
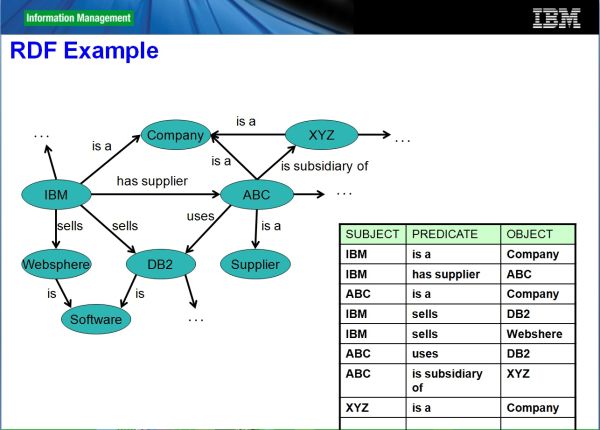
In graphenorientierte Dateiformat wie dem Resource Description Framework, kurz RDF, werden Informationen als Graphen in Form von Triples abgelegt. Quelle: IBM.
Schneller im Arbeitsspeicher: In-Memory-Datenbanken
Für die beschleunigte Verarbeitung extrem großer Datenmengen haben sich auch In-Memory-Datenbanken etabliert. Sie sind besonders bei Analytics-Aufgaben relevant, wenn riesige Daten ausgewertet werden sollen. Diese Datenbanken machen sich die Tatsache zu nutze, dass das Speichern und Abrufen von Daten im Arbeitsspeicher (RAM) deutlich schneller vor sich geht als von Festplatten.
In-Memory-Datenbanken laden deshalb das gesamte Datenvolumen – zusammen mit den Datenbankanwendungen – in den Hauptspeicher, der dann entsprechend groß dimensioniert sein sollte. Dort kann die sehr schnelle Analyse erfolgen. Da das Laden und Lesen von der Festplatte entfällt, lassen sich die Daten sehr schnell abrufen und analysieren.
Die Analyse von Geschäftsdaten kann mit In-Memory-Datenbanken praktisch in Echtzeit ausgeführt werden und nimmt nicht Tage oder Wochen in Anspruch. Wichtige Entscheidungen lassen sich mithin viel schneller treffen. Ob es sich dabei um SQL- oder NoSQL-Datenbanken handelt ist nicht relevant. Festplatten werden prinzipiell nicht benötigt und nur für administrative Prozeduren verwendet.
Mit HANA bietet SAP beispielsweise eine auf In-Memory-Technik basierende BI-Applikation. HANA wurde Mitte 2010 von ihren geistigen Vätern Hasso Plattner und Technik-Chef Vishal Sikka als Hochleistungsplattform für die analytische Bearbeitung großer Datenmengen entwickelt. Siehe auch den Beitrag auf dem QSC-Blog „Was ist eigentlich SAP HANA?“
Was Unternehmen und Analysten sagen
In-Memory-Datenbanken sind inzwischen auch längst ein Thema in den Unternehmen. Laut einer von TNS-Infratest im Auftrag von T-Systems durchgeführten Studie haben 43 Prozent der deutschen Unternehmen In-Memory-Technologien zur Datenauswertung bereits im Einsatz haben oder planen dies für die nahe Zukunft. Laut Studie verweisen 90 Prozent derjenigen, die In Memory bereits nutzen, auf gute und sehr gute Erfahrungen. 36 Prozent der Befragten sehen den Einsatz von In-Memory-Anwendungen bevorzugt in Performance-kritischen Bereichen.
„Die Frage, ob In-Memory-Analysen in Zeiten von Big Data eine Rolle spielen, kann mit einem klaren Ja beantwortet werden“, sagt Frank Niemann, Principal Consultant Software Markets bei PAC und Autor der Studie „In Memory-Datenanalysen in Zeiten von Big Data“. Die Mehrheit der deutschen Unternehmen betrachtet In-Memory-Verfahren allerdings zunächst als Ergänzungsbaustein für zeitkritische Analysen. Immerhin bereits knapp 20 Prozent der Unternehmen sehen in ihnen aber eine wichtige Antwort auf die Herausforderungen durch Big Data. Sie erwarten, dass In-Memory-Systeme zentraler Bestandteil von Datenanalyseumgebungen werden.
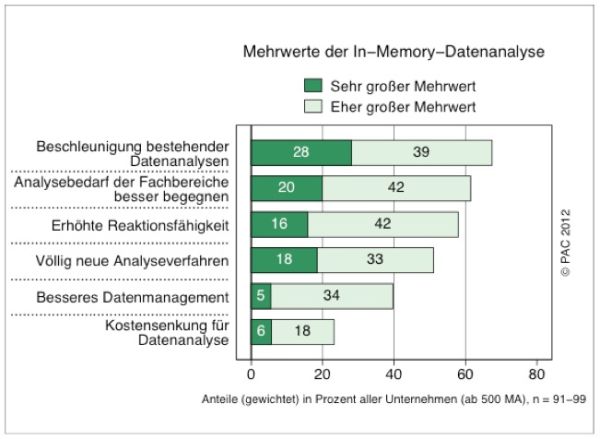
Laut einer PAC-Studie profitieren Unternehmen von In-Memory-Datenbanken vor allem durch schnelle Datenanalysen. Quelle: PAC.
„Unternehmen erkennen zunehmend die Chancen, die Big Data ihnen bietet“, sagt auch Bodo Koerber, Director of Information Management, IBM Software Group, IBM Deutschland. „Datensammlungen sind erst dann sinnvoll, wenn sie zeitnah analysiert und komplexe Zusammenhänge aus ihnen herausgelesen werden. Aber es gibt kein „one size fits all“ – die konkreten Anforderungen eines Unternehmens bestimmen, welcher Technologiemix ihm den höchsten Nutzen bringt.“
Ein einziges Datenreservoir, das das Big-Data-Problem zentral und unkompliziert löst, wird es wohl in Zukunft nicht geben. Das sieht auch Experton-Group-Analyst Andreas Zilch so: „Es wird nicht die Big-Data-Superlösung geben.“
Unsere Big-Data-Serie im Überblick:
- Big Data: Was dahinter steckt
- Was kann Big Data?
- Revolution oder Evolution: Wie Big Data die IT verändert
- Big Data: Teile und herrsche mit Hadoop
- NoSQL und In Memory – die neuen Datenbanken für Big Data
Kommentare
Ein Teil unserer Crew will auf eine spaltenorientierte Datebank umsteigen weil die Abfragen bei unserer großen Datenmengen deutlich schneller sein sollen. Ich scheue den Umstellungsaufwand. Hat jemand Erfahrung mit diesen Datenbanken? Lohnt sich ein Umstieg?